折腾Clash配置的时候,最让你头秃的是不是那个fallback策略组?明明照着教程抄了,结果要么连不上,要么延迟爆表。我刚开始也这样,后来啃了大半个月的源码和文档,才搞明白这玩意儿到底在干嘛。
说白了,fallback就是给代理加了个“备用方案”。当你主代理挂了或者太慢,它自动切到备选节点。但很多人组建策略组时,逻辑搞反了——以为优先级越高越好,其实恰恰相反。
问题一:fallback的“心跳检测”到底怎么工作的?
先看机制。Clash每隔几秒(默认5秒)向你的目标网站发一个“健康检查”请求——说白了就是个HTTP HEAD。如果主节点连续三次超时或报错,fallback策略就会触发,把流量切到备选节点。
但关键在这里——它不会一直切来切去。一旦主节点恢复,它不会马上切回来,而是等一个“稳定期”(默认30秒)。这个设计是为了避免网络抖动导致反复切换,说白了就是防止你打游戏时突然断流。
我遇到过有人把健康检查间隔设成1秒,结果路由器直接炸了——因为每个节点都要测,节点一多,CPU负载飙升。实测经验:节点超过10个,间隔至少调成10秒。
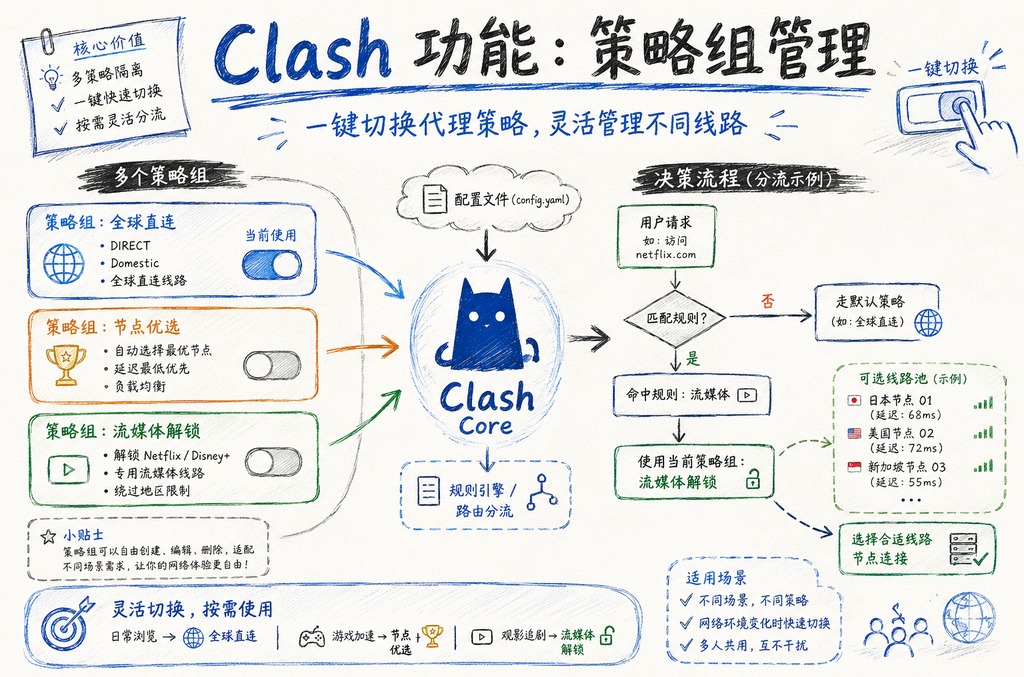
问题二:怎么配置才算“合理组建”?
坦白讲,很多教程教你把所有节点塞进一个fallback组,这是大坑。正确的做法是分组:比如把香港节点放主组,日本和新加坡当备选。
举个例子:
- 主组:香港节点A、B(延迟<50ms)
- 备组1:日本节点C、D(延迟50-100ms)
- 备组2:新加坡节点E(延迟>100ms)
这样组建后,fallback策略组会优先走主组。主组全挂了才试备组1,再不行才到备组2。我自己的配置里甚至加了个“直连”兜底——防止所有代理都炸了直接断网。
组建的时候要注意:备选节点的类型最好混搭,比如一个用SS,一个用Trojan。因为不同协议被封的概率不一样,混合起来能提高稳定性。这个思路在Clash策略组组建的进阶玩法里也适用。
问题三:策略组组建后,延迟反而高了?
常见问题。原因通常是健康检查的“并发数”设置太高。默认是10,意思是同时测10个节点。如果你的宽带只有20M上行,10个并发请求直接塞满带宽,导致正常上网都卡。

解决办法:把并发数降到3-5。别担心测速变慢——反正检测间隔是5秒,慢一两秒不影响。我实测降到3后,网页加载速度反而快了,因为带宽不再被挤占。
另一个坑是“目标URL”的选择。很多教程用google.com,但国内访问谷歌本身就可能被干扰。我建议用fast.com或者cloudflare.com——这两个CDN节点多,响应快,检测结果更准。
问题四:fallback和“自动测速”到底选哪个?
直接给结论:fallback适合你手头有稳定主力节点的情况。自动测速适合节点质量都差不多、想自动选最优的场景。
但自动测速有个致命问题——它每次都会切换节点,导致连接中断。打游戏或者看直播时,突然切节点掉线,你能忍吗?
所以我的建议:日常使用就用fallback,只在主节点挂了才切。真的,别迷信“智能切换”,稳定比速度更重要——毕竟延迟高50ms你感觉不到,但断线重连你绝对能骂娘。
如果你还是想折腾自动测速,可以参考Clash负载均衡配置里的思路,但坦白讲,99%的用户用fallback就够了。
问题五:组建后怎么测试它到底管不管用?
简单粗暴——手动禁掉主节点。比如你用的是Windows客户端,在配置文件里把主节点的“port”改成一个不存在的端口号,然后保存重载。打开命令行ping一个外国网站,看延迟有没有变高(切到备选节点时,延迟通常会有明显变化)。
我习惯同时开两个终端:一个持续ping百度,一个ping谷歌。如果百度一直通但谷歌断了又恢复,说明fallback生效了。实测案例:有次主节点被墙,fallback在15秒内切到了备选节点,全程我在看视频,只卡了5秒左右——效果还行。
记住,组建完一定要做压力测试。30分钟内连续开关主节点3-5次,看策略组会不会疯掉。如果出现频繁切换,说明“稳定期”设置太短,建议从30秒调高到60秒。
最后说一句:Clash fallback策略组组建这事,别贪多。节点不是越多越好,5个高质量节点+合理分组,绝对比20个垃圾节点强。别问我怎么知道的——都是踩坑踩出来的。